
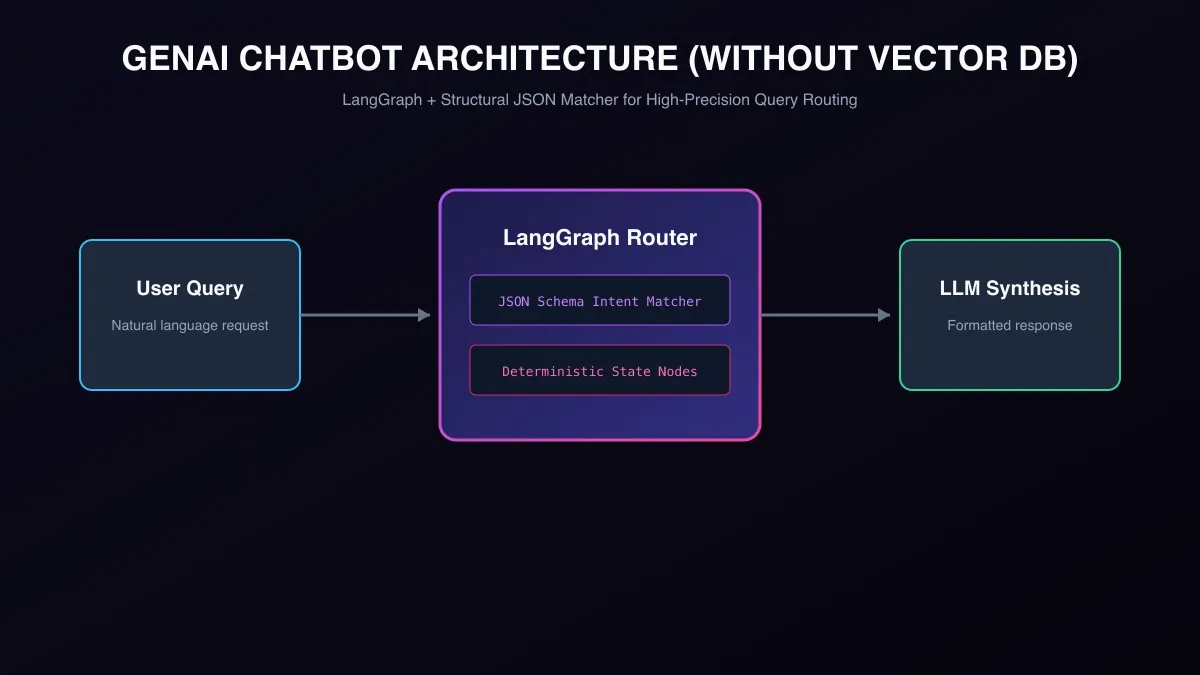
Most GenAI chatbot discussions jump straight to a vector database. That can be the right answer, but is not always the first answer. For Nykaa's SuperStore, the immediate goal was to ship a production conversational experience that could retrieve product context, connect to commerce flows, and remain simple enough for the team to inspect and test.
This is the public-safe version of how I approached it: LangGraph for orchestration, TypeScript and Next.js for the product surface, and a custom JSON embedding retrieval layer instead of a dedicated vector DB.
Why we skipped the vector DB
A vector database is useful when scale, indexing needs, filtering complexity, or retrieval volume justify the extra system. It also adds operational surface area: another service to provision, observe, secure, and tune.
For this SuperStore use case, the first production need was narrower. We needed semantic retrieval over prepared product and commerce context, with enough speed and clarity to integrate into an existing TypeScript stack. Starting with structured JSON embeddings gave us three advantages:
- Lower infrastructure overhead for the first production version.
- Better debuggability because the retrieval payloads stayed inspectable.
- Faster iteration because the schema lived close to the application code and tests.
The tradeoff is clear: this approach is not a universal replacement for vector infrastructure. It fits well when a lighter retrieval layer can handle the corpus, query patterns, and latency budget.
Structuring product data as JSON embeddings
The key decision was to avoid treating embeddings as an opaque blob of magic. We normalized product and catalogue inputs into a JSON shape that could carry both the embedding representation and the metadata needed for commerce responses.
At a high level, each prepared item included:
- A stable identifier for the product or catalogue entity.
- Searchable text derived from product attributes and commerce context.
- Embedding output for semantic matching.
- Metadata needed to produce product-aware responses.
- Fields that made debugging and test assertions easier.
That structure matters because a chatbot failure is rarely just a model failure. It can be bad source text, missing metadata, a ranking issue, an orchestration issue, or a UI integration issue. Keeping the retrieval data readable helps isolate the layer that actually needs work.
LangGraph orchestration
LangGraph was useful because the chatbot had more than one step. The system needed to interpret the user message, decide when to retrieve context, run semantic matching, prepare product-aware context, and return an answer that could connect back to commerce flows.
The graph structure made those responsibilities explicit. Instead of burying everything in one handler, each node could own one concern: intent handling, retrieval, ranking, response preparation, and fallback behavior.
That structure also made review easier. A teammate can reason about a graph node faster than a large prompt-and-handler block where retrieval, prompting, and response formatting are all mixed together.

95% Jest coverage for a GenAI feature
Testing a GenAI feature does not mean snapshotting every generated sentence. That creates brittle tests and misses the real risks.
The useful tests were around deterministic boundaries:
- Input normalization for product and catalogue data.
- Embedding payload schema and required metadata.
- Retrieval ranking behavior for known query fixtures.
- Graph branching for supported, unsupported, and fallback paths.
- UI state transitions around loading, empty states, and commerce handoffs.
The goal was release confidence, not artificial coverage. With a systematic Jest strategy, the targeted SuperStore surface reached 95%+ unit test coverage while still keeping tests focused on behavior the team could control.
What I would do differently at 10x scale
At 10x scale, I would revisit the storage and indexing layer. A dedicated vector database or managed vector search can become the right choice when the catalogue grows, filtering needs become more complex, or retrieval latency starts depending on more advanced indexing.
I would also invest earlier in offline evaluation: saved query sets, expected retrieval candidates, precision checks, and regression dashboards for retrieval quality. Unit tests protect deterministic code paths, but retrieval quality also needs evaluation over realistic query sets.
Production GenAI work is still production engineering. The model matters, but so do data shape, observability, test boundaries, latency, rollback paths, and the ability for another engineer to understand the system six months later.